

OpenAI ha exhibido este viernes sus nuevos modelos Sol, Luna y Terra, pertenecientes a la esperada serie GPT-5.6. Sin embargo, su previsualización pública —como era previsible— no ha sido el mejor despliegue de su historia. En las oficinas de OpenAI lo tenían muy claro: lo que le ocurrió hace unas semanas a Anthropic con Fable era una historia que, bajo ningún concepto, querían protagonizar.
Aplicando el sabio refrán de «cuando veas las barbas de tu vecino cortar, pon las tuyas a remojar», la compañía ha mostrado estos modelos agachando la cabeza ante el águila calva. Lo han hecho integrando «el mayor número de salvaguardas» tras «haber dedicado varias semanas a someterlo a pruebas extremas para blindarlo frente a ciberataques y usos indebidos»; una decisión que parece orientada no tanto a proteger a la comunidad, sino para evitar la ira del gobierno federal y sus «socios de confianza».
Y es que la verdadera cuestión de fondo es el control, porque la geopolítica está hoy más de moda que nunca. El retiro de Claude Fable tras su lanzamiento ha supuesto un cambio de paradigma insoslayable para la industria, que como pronto, se ha manifestado en un lanzamiento sumamente restringido.
A pesar de que la empresa ha intentado calmar los ánimos asegurando que se trata de una medida temporal, mientras se define un proceso estándar bajo el marco de la reciente Orden Ejecutiva 14409 sobre ciberseguridad, ha quedado claro que lo de Open en OpenAI es hoy un simple vestigio vaciado de valor de una época pasada en la que se prometía que esta tecnología iba a ser totalmente libre, accesible y abierta para la ciudadanía.
En cuanto a Sol, Terra y Luna, estos han sido diseñados para resolver tres necesidades computacionales distintas. Sol es el modelo más capaz hasta la fecha, apoyado en un nuevo modo Ultra basado en subagentes. Terra mantiene un equilibrio técnico reduciendo el coste a la mitad, mientras que Luna llega como la opción más rápida y asequible 5 veces mas barato que Sol. El contraste entre estos surge especialmente en escenarios complejos como pruebas prolongadas de auditorías de seguridad, donde Terra y Luna desploman su eficacia y disparan el consumo.
Para limitar el «uso inadecuado» de la herramienta, OpenAI ha desplegado una arquitectura de seguridad transversal donde, tras 700.000 horas de GPU A100 a red teaming automatizado, se ha probado que Sol identifica vulnerabilidades sin cruzar el umbral Cyber Critical al no generar autónomamente cadenas completas de explotación.
Sol
Sol es el «astro rey» de GPT-5.6 y su modelo frontera insignia. Su principal avance se encuentra en el razonamiento agéntico: la capacidad de sostener flujos de trabajo prolongados, utilizar herramientas y corregir errores, introduciendo un modo Ultra basado en subagentes para dividir tareas complejas.
En programación y asistencia agéntica, Sol Ultra alcanza un 91,9 % de efectividad y la versión estándar un 88,8 % (por encima del 88,0 % de Claude Mythos 5), en pruebas que exigen planificación y coordinación de herramientas. En análisis de genomas y datos biológicos, alcanza aproximadamente un 31 % de puntuación con 30.000 tokens de salida frente al 23 % de GPT-5.5.

En ciberseguridad, alcanza una cobertura del 73-74 % en investigación de vulnerabilidades y cerca del 34 % de éxito en pruebas de explotación controlada a 6 horas (con un coste aproximado de 138 dólares). No obstante, no cruza el umbral Cyber Critical, ya que identificó fallos de explotación pero no generó de forma autónoma una cadena funcional completa de exploit.
El modelo se comercializará a 5 dólares por millón de tokens de entrada y 30 dólares por salida. OpenAI también prevé desplegarlo en Cerebras en julio, con velocidades de hasta 750 tokens por segundo para clientes de confianza.
Terra
Terra está diseñado para tareas cotidianas y cargas de trabajo donde se necesita un rendimiento técnico sólido sin asumir el coste del modelo más avanzado.
En programación, Terra alcanza un 84,3 %, el mismo resultado atribuido a Claude Fable. Esta cifra lo sitúa por encima de GPT-5.5, que marca un 83,4 %, y lo convierte en una opción competitiva para automatización, asistencia técnica y tareas de desarrollo que no requieren el modo de razonamiento más intensivo de Sol.
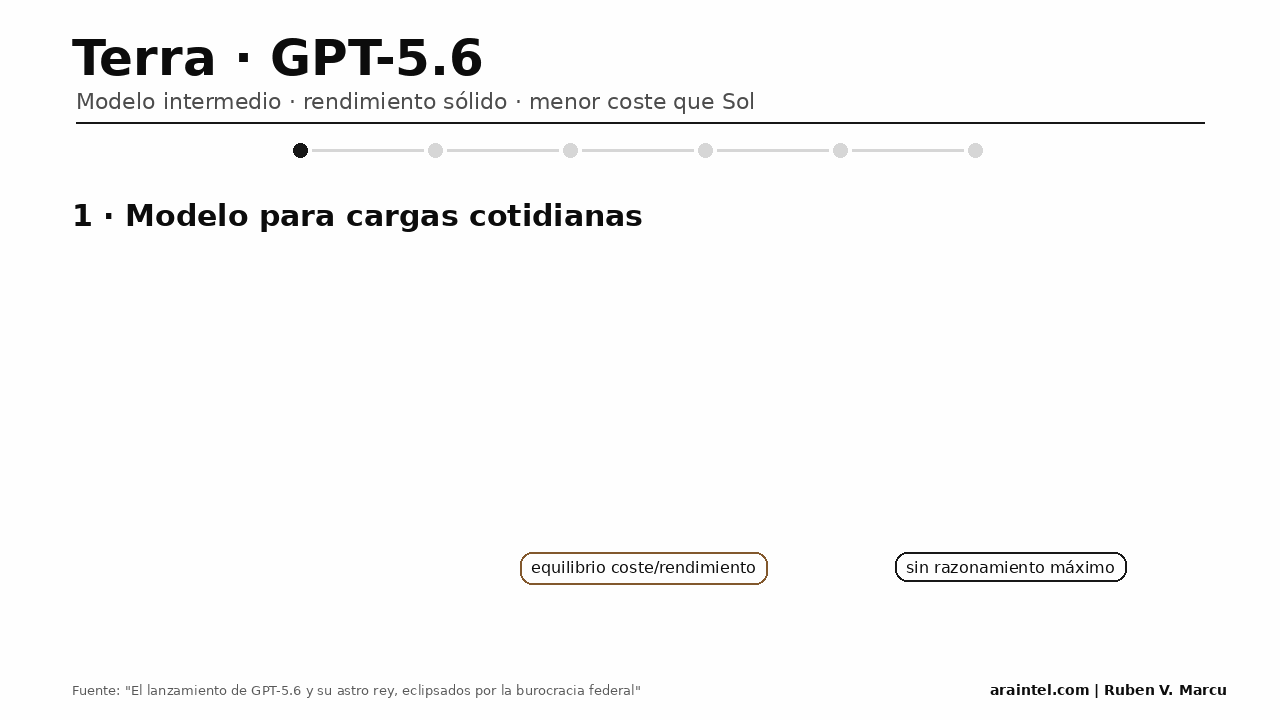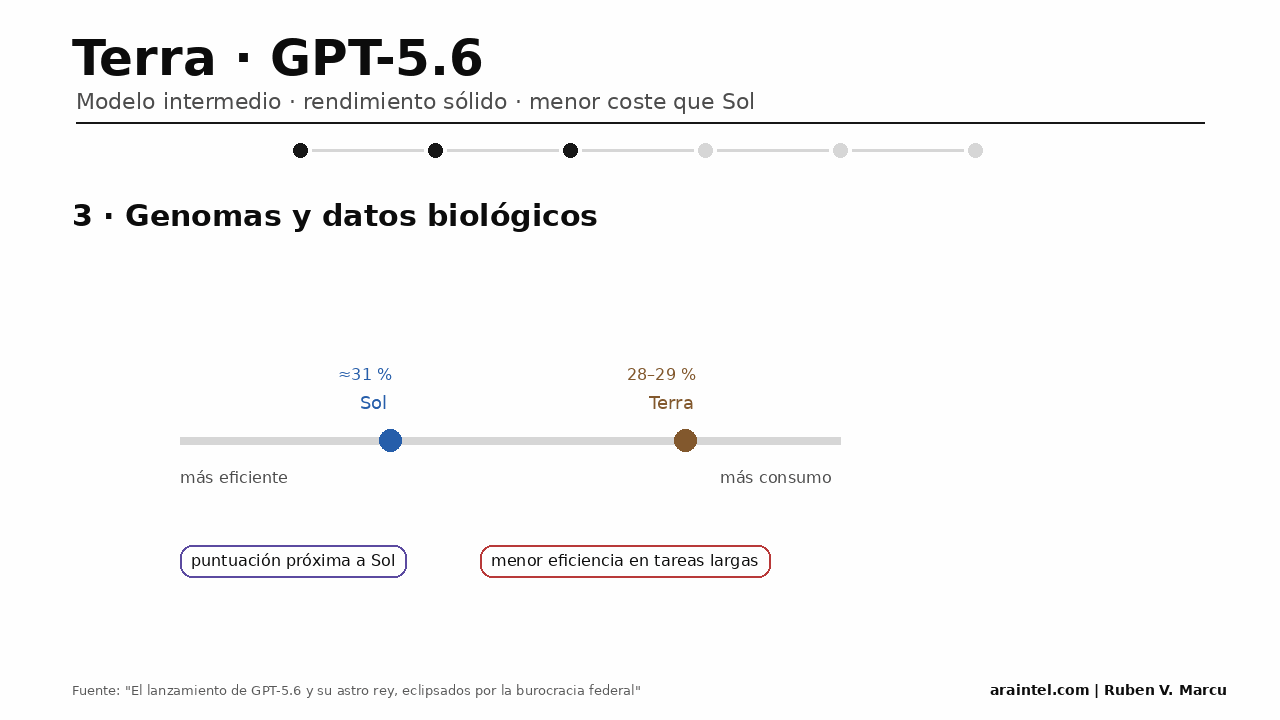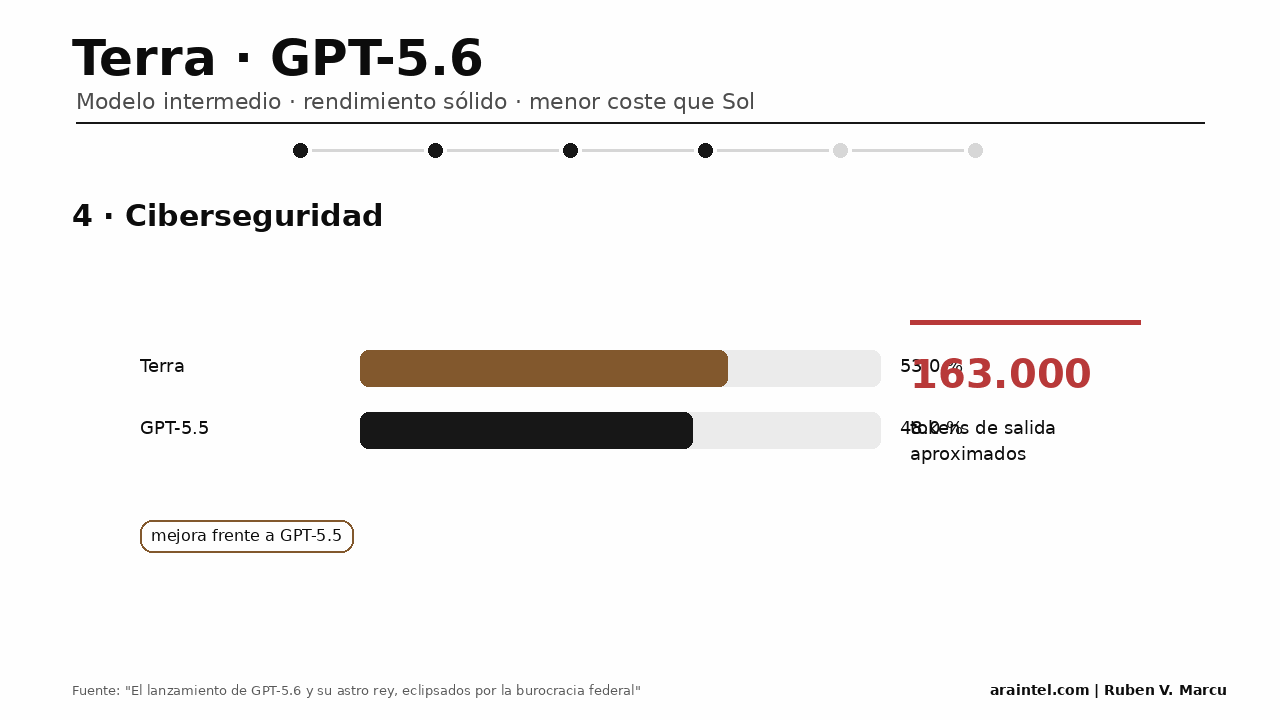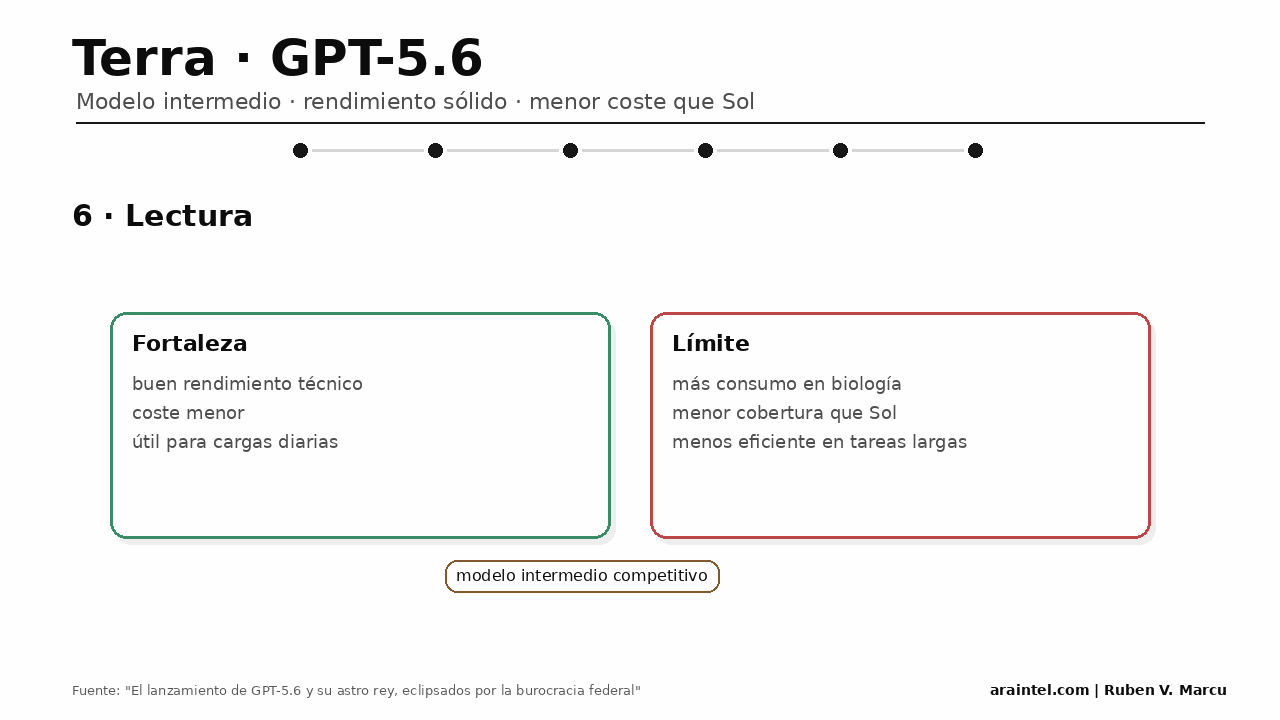
En análisis de genomas y datos biológicos, Terra mantiene un rendimiento cercano al 28-29 %, aunque con un consumo mayor: alrededor de 49.000 tokens de salida. Esto lo deja próximo a Sol en puntuación, pero por debajo en eficiencia, especialmente en tareas largas donde el número de tokens condiciona coste y latencia.
En ciberseguridad, Terra alcanza una cobertura aproximada del 53 % con unos 163.000 tokens de salida. La cifra mejora el 48 % atribuido a GPT-5.5, aunque queda lejos de Sol tanto en rendimiento como en eficiencia. Terra costará 2,50 dólares por millón de tokens de entrada y 15 dólares por millón de tokens de salida.
Luna
Luna es el modelo más económico de la serie GPT-5.6 y prioriza velocidad de respuesta y reducción de costes, por lo que queda orientado a escenarios donde la eficiencia económica pesa más que la máxima capacidad técnica.
En programación, Luna alcanza un 82,5 %, una cifra inferior a Sol y Terra, pero todavía competitiva frente a modelos externos como Claude Opus 4.8, que figura con un 78,9 %. Esto permite situarlo como una opción válida para tareas de asistencia, automatización ligera y flujos donde el coste sea un factor determinante.

En análisis de genomas y datos biológicos, su rendimiento cae de forma más clara. Luna se sitúa aproximadamente en el 14-15 % y requiere unos 56.000 tokens de salida, lo que muestra una menor eficiencia en tareas científicas de largo recorrido. En este tipo de cargas, la opción de menor coste no necesariamente implica menor coste operativo si el consumo de tokens aumenta demasiado.
En ciberseguridad, Luna alcanza cerca del 38 % de cobertura, una zona próxima a GPT-5.4. Su rendimiento es el más contenido de la familia y lo aleja de las tareas avanzadas de investigación de vulnerabilidades o explotación controlada. Luna se comercializará a 1 dólar por millón de tokens de entrada y 6 dólares por millón de tokens de salida. Es la opción más barata de GPT-5.6 y la más adecuada para despliegues amplios donde no se requiera gran nivel de razonamiento.
Arquitectura de seguridad
Para contener este nuevo nivel de autonomía, OpenAI ha implementado una protección por capas que utiliza clasificadores en tiempo real para revisar posibles abusos durante la generación; en casos de alto riesgo, la respuesta se pausa para que otro modelo analice el contexto. Además, la tecnológica dedicó más de 700.000 horas equivalentes de procesamiento en GPUs A100 a procesos de red-teaming automatizado, con el objetivo de localizar y neutralizar jailbreaks.
Sin embargo, este blindaje tiene un coste operativo para los usuarios. Debido a esta arquitectura estricta, durante la fase de preview las salvaguardas podrían provocando bloqueos, rechazos y respuestas más lentas. OpenAI reconoce abiertamente que algunas solicitudes completamente legítimas, como la investigación en ciberseguridad defensiva, se verán afectadas negativamente por estas medidas de contención.
Conclusión
GPT-5.6 no llega como una victoria técnica, sino como una rendición elegante. El mensaje de fondo es inequívoco: la IA de frontera ya no se lanza cuando está lista, sino cuando encaja en el tablero regulatorio y geopolítico de sus dueños.
De ahí la sensación incómoda que deja este estreno. En lo técnico, los avances son reales —sobre todo en eficiencia y gestión de tokens—, pero nacen vigilados y condicionados. Tras el retiro forzoso de Claude Fable, ningún laboratorio quiere ser el próximo en cruzar la línea, y OpenAI lo ha entendido a la perfección.
El resultado es una paradoja que la propia compañía ya no puede disimular. Lo de OpenAI sigue siendo inteligencia artificial de frontera, sí; pero de «abierta» apenas conserva el nombre. Cada nueva generación parece menos libre, menos accesible y más dependiente de quién tiene permiso para tocarla primero. Y esa, más que cualquier benchmark, es la verdadera métrica que define a GPT-5.6.








