

El método malicioso que los atacantes utilizan para tratar de «clonar» modelos de IA.
A lo largo del último año, se han dado varios casos de los llamados distillation attacks, que en castellano sería algo como «ataques de destilación». Este método es un tipo de ataque dirigido a modelos de inteligencia artificial, que no busca comprometer activos ni causar disrupciones. En su lugar, el objetivo de un distillation attack es la propiedad intelectual del creador del modelo.
El fin último es replicar con la mayor fidelidad posible un modelo de IA, tratando de «clonarlo», robando las capacidades del modelo que está siendo atacado.
La destilación es el proceso de separar los componentes o sustancias de una mezcla (líquida). La química es irrelevante aquí, pero el nombre no es casualidad. Así como en un laboratorio se usa la ebullición selectiva y la condensación para separar unos componentes de otros, los distillation attacks usan peticiones cuidadosamente diseñadas para inferir el funcionamiento interno de un modelo y tratar de replicar su inteligencia.
Extrayendo inteligencia de la inteligencia
¿Cómo es posible que puedan extraer las capacidades de un modelo y replicarlas? Para comprenderlo, es necesario entender cómo funciona por dentro un LLM.
La idea original viene de un paper de 2015: «Distilling the Knowledge in a Neural Network» por Geoffrey Hinton, Oriol Vinyals y Jeff Dean. En un principio, la destilación se ideó como un método para entrenar modelos pequeños con un modelo más grande. En 2015, la meta de esta investigación era «compactar» modelos, ya que la viabilidad comercial de mantener un gran modelo en producción no era la misma que ahora. Mediante la destilación, se podía transferir el conocimiento de un gran modelo a un modelo más pequeño, apto para producción.
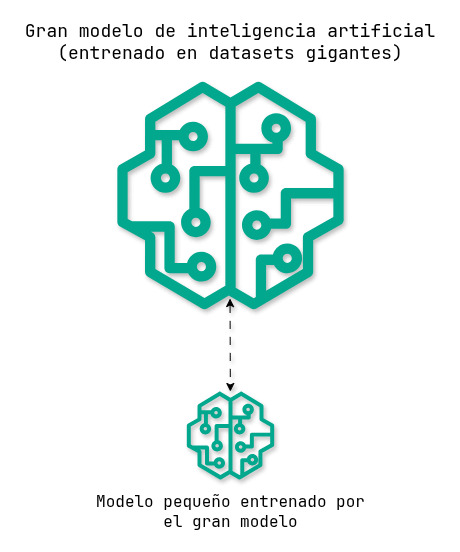
Un equipo que destila su propio modelo grande para crear uno pequeño tiene acceso directo al primero, y puede entrenar al pequeño sin intermediarios. Esto puede servir para:
- Compactar el modelo, para adaptarlo a dispositivos menos capaces como móviles.
- Especializar modelos: un gran modelo generalista puede dar entrenamiento hiperespecífico y producir un modelo compacto y concreto de muy buena calidad.
- Reducir los costes de inferencia.
Los gigantes del sector de la IA hacen esto continuamente, para investigar, crear nuevos productos, adaptar sus modelos a casos especiales…
Un actor malicioso, en cambio, no tiene acceso directo al gran modelo, solo puede comunicarse con él en calidad de cliente, vía API o chat. Los ataques de destilación los sufren empresas que comercializan grandes y potentes LLMs, como Anthropic, Google, OpenAI o X. Como el acceso es más limitado, los atacantes deben inferir la mayor cantidad de matices del LLM en una ventana reducida y con poco margen de error. Los proveedores, por su parte, protegen su propiedad intelectual y desarrollan medidas para frenar estos ataques.
Ataques por destilación
Este escenario, en el que un atacante no tiene ninguna o mínima información sobre el funcionamiento interno de un sistema, se conoce como black-box o caja negra. Es el caso de los actores que tratan de atacar a los grandes LLMs: Claude, ChatGPT, Gemini… Todos son de código cerrado, es decir, los adversarios apenas tienen acceso al funcionamiento interno del modelo.
Técnicamente, knowledge distillation o destilación de conocimiento es la técnica de aquel paper de 2015, pero se llama comúnmente distillation attack a los ataques de extracción de modelo que se aprovechan de dicha técnica para comprometer la propiedad intelectual de los gigantes del sector.
Los MEA (model extraction attacks) aprovechan accesos legítimos al modelo atacado para realizar una serie de consultas diseñadas para «extraer» la capacidad del modelo y utilizarla para entrenar otras IAs. A diferencia del model extraction clásico, que buscaba reconstruir los parámetros internos del modelo, aquí el objetivo es replicar su comportamiento. Utilizando accesos normales y corrientes como una cuenta de usuario cualquiera, los atacantes empiezan a realizar consultas cuidadosamente diseñadas para producir respuestas de alto valor, que luego almacenan para entrenar su propio modelo.

En febrero de 2026, Anthropic reveló ataques de actores chinos que generaron 16 millones de interacciones desde 24.000 cuentas diferentes. La potencia de sus modelos los convierte en blanco frecuente, y Anthropic afirma detectar ataques de este tipo de forma recurrente.
¿Quién anda detrás de esto?
No se trata de un ataque que realiza un script-kiddie: la barrera técnica para diseñar el ataque y entrenar el modelo es tan alta como la económica, ya que consumir esa cantidad de tokens en APIs de pago cuesta una fortuna. Este ataque requiere organización, experiencia, capacidad técnica y dinero, además de una infraestructura sólida.
Los actores de estos intentos no son amateurs: son empresas rivales, organizaciones criminales y —posiblemente— grupos financiados por Estados. El propio Anthropic ha atribuido ataques a sus modelos a distintas compañías rivales, como DeepSeek, Moonshot y MiniMax.
Para evitar las limitaciones impuestas en China y otras medidas de seguridad de distintas organizaciones, los atacantes controlan proxies que revenden el acceso a herramientas de este tipo a escala. Estas redes de proxies son resistentes: cuando una cuenta es baneada, otra toma rápidamente su lugar, hasta el punto de que una sola red llegó a operar 20.000 cuentas de forma simultánea.
La motivación
Hay una infraestructura criminal potente, y ciertos grupos dedican muchos recursos técnicos y económicos a llevar a cabo estos ataques a gran escala. La pregunta es: ¿por qué? La respuesta es sencilla. Los modelos de vanguardia son extremadamente potentes, y su valor comercial, militar y técnico es enorme. Además, es un producto expuesto. No puede desmontarse físicamente como un teléfono móvil, pero sí resulta relativamente fácil de copiar, a diferencia de un software cerrado como Windows.
Este balance entre incentivos y viabilidad es la clave. Para las empresas, las ganancias potenciales; para las organizaciones criminales y los Estados, el uso sin restricciones de una herramienta extremadamente potente.
Cómo protegerse al respecto
Hay incentivos y medios, justo lo necesario para que los intentos sean constantes. Y, sin embargo, ningún atacante ha logrado clonar por completo un modelo como Claude. ¿Cómo hacen los proveedores para proteger sus modelos? Hay dos formas principales de hacerlo.
Métodos «tradicionales»
La primera forma es utilizar los mecanismos de defensa generalistas y buenas prácticas en términos de ciberseguridad, con especial énfasis en medidas que eviten de forma activa el tráfico automatizado: firewalls de capa 7, CAPTCHAs, análisis heurístico de conducta… Las organizaciones punteras tienen sus formas de detectar los patrones de ataques de esta naturaleza y tratar de detenerlos en la propia infraestructura, pero si eso falla, quedan las defensas del propio modelo.
Métodos específicos
Por otro lado, están las técnicas específicas de inteligencia artificial. Todo el mundo ha oído hablar del jailbreak y los guardrails, pero evitar generar contenido polémico o realizar acciones maliciosas no son las únicas funciones de estas medidas. Las peticiones utilizadas por los actores maliciosos en ataques de destilación no son comunes, y pueden ser detectadas por el propio modelo en el procesamiento del prompt.
Los LLMs cada vez tienen más controles y guardarraíles cuando salen al público, y buena parte de ellos no busca prevenir el uso malicioso, sino evitar la exfiltración de conocimiento. De hecho, parte del entrenamiento del modelo consiste en aprender a identificar cuándo se le está intentando destilar, para activar sus protocolos de defensa al detectar un intento.
En definitiva
Los modelos de inteligencia artificial se están convirtiendo en uno de los productos más valiosos y peligrosos del mundo. Esto supone un atractivo enorme para quienes quieren darles un uso malicioso. Y, como siempre, a las organizaciones les cuesta estar a la altura de los atacantes y mantener defensas más avanzadas que los métodos de ataque.
La inteligencia artificial bien podría ser el puente por el que cruzar a un mundo en el que la situación se invierte, y los defensores tienen por primera vez en la historia la mano ganadora. Pero para llegar ahí primero hay que acabar el puente, y alcanzarlo. Ahí es donde los responsables de los modelos deben asumir la responsabilidad de protegerlos, y utilizarlos de manera cuidadosa.
Como usuarios, tenemos la responsabilidad y el deber de entender los productos que consumimos, para desarrollar un criterio con el que tomar buenas decisiones y exigir, mediante la demanda, productos de calidad. Por esto es vital comprender algo tan disruptivo como la inteligencia artificial. Hemos de comprender el mundo en el que vivimos, y las cosas que compramos —y sobre todo las que no compramos—, si no queremos que se vuelvan en nuestra contra, literal o figuradamente.








